
PGKAZ: PostgreSQL + Alta Disponibilidad
- febrero 17, 2021
PGKAZ (“PostgreSQL, Keepalived, Zabbix”) es un software desarrollado por el Equipo de Innovación de Know-How que permite montar un clúster de dos bases de datos PostgreSQL en activo-pasivo, con una IP virtual para la base máster y una IP virtual para la base standby. Las IPs virtuales son manejadas por Keepalived y se incorpora Zabbix como un “tercer nodo”, con vista global sobre el clúster, que permite determinar en cada momento, en base al estado de cada nodo, la asignación de roles (máster/standby) a los nodos del clúster.
Los componentes principales son los siguientes:
- PostgreSQL como motor de base de datos en ambos nodos
- Keepalived para el manejo de IPs virtuales, scripts de control y cambios de estado
- Zabbix como sistema de alertas y pasaje de información del clúster entre los nodos, y visualización de datos propios del clúster entre los nodos, y visualización de datos propios del mecanismo

Funcionamiento general del PGKAZ
En términos generales, la ejecución del PGKAZ consiste en repetir indefinidamente un ciclo de trabajo, idéntico en cada nodo, que consta de las siguientes etapas:
- Ejecutar un chequeo interno para determinar si el PostgreSQL está en condiciones de oficiar como máster
- Reportar el resultado a Keepalived (KA)
- Reportar el resultado a Zabbix
- Si el chequeo es afirmativo (el nodo puede ser máster): quedarse en espera hasta el próximo ciclo
- Si el chequeo es negativo (el nodo no puede ser máster):
-Si actualmente es standby: quedarse en espera hasta el próximo ciclo
-Si actualmente es máster: pasarse a standby a nivel de PostgreSQL
Con los datos reportados a Zabbix, el servidor Zabbix visualiza el estado global del clúster y determina, en cada ciclo, el estatus que tendrá el clúster en el ciclo siguiente, según este detalle:
- Si ambos nodos reportan que pueden ser máster, se mantiene el máster actual
- Si un nodo reporta que puede ser máster y el otro reporta que no puede serlo:
-Si el máster actual es el nodo que puede ser máster, se mantiene el máster actual
-Si el máster actual es el nodo que no puede ser máster, se ejecuta un switchover, cambiando de roles
Con los datos reportados a KA, el Keepalived visualiza el estado global del clúster y determina, en cada ciclo, dónde deben ir las IPs virtuales y cómo debe configurarse el PostgreSQL en cada nodo (máster/standby), según este detalle:
- Si ambos nodos reportan que pueden ser máster, se mantiene el máster actual
- Si un nodo reporta que puede ser máster y el otro reporta que no puede serlo:
-Si el máster actual es el nodo que puede ser máster, la vip-master y la vip-slave van al nodo máster (queda como único nodo activo del clúster)
-Si el máster actual es el nodo que no puede ser máster, la vip-master y la vip-slave van al nuevo nodo máster (en este caso, se habrá ejecutado un switchover)
De manera independiente, el KA envía “pulsos” (mensajes de red) periódicamente entre los nodos del clúster, de manera que si el standby deja de ver al máster, se promueve el standby a nivel de PostgreSQL, y se migran ambas VIPs para el nuevo máster. A su vez, esta modificación en el clúster se reporta a Zabbix, y Zabbix actualiza el estado del clúster en ambos nodos, para ser evaluado en el siguiente ciclo.
También está prevista la existencia (opcional) de un tercer nodo de PostgreSQL que oficie como segundo standby (en cascada o en árbol). Este tercer nodo, además de tener una copia adicional de la base de datos (idealmente en otro datacenter), tiene la capacidad de tomar parcialmente el rol de Zabbix en caso de indisponibilidad del Zabbix server o baja del agente de Zabbix en alguno de los nodos principales.
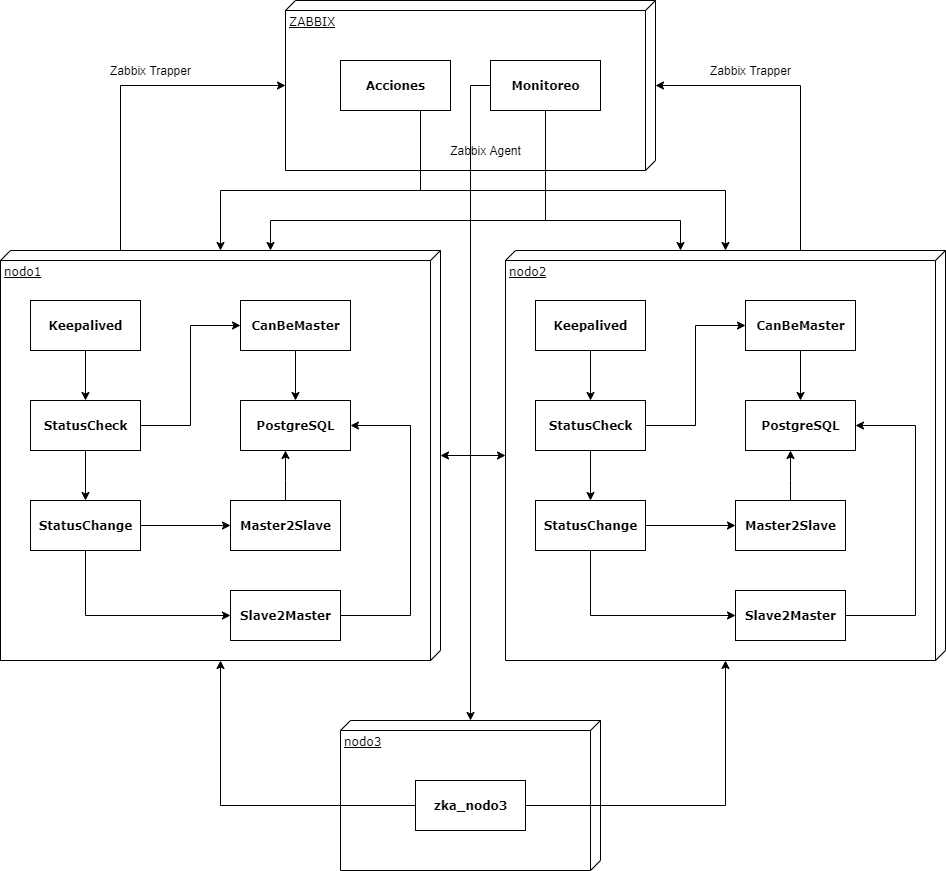
Keepalived: Todos los componentes del PGKAZ locales a los nodos, se ejecutan bajo el control de este componente, que representa el proceso principal a nivel del sistema operativo Linux. Keepalived levanta la máquina de estados y ejecuta el ciclo principal explicado anteriormente (y cuyas transiciones se van a explicar más adelante en el diagrama de flujo), delegando la ejecución al componente StatusCheck en cada iteración.
StatusCheck: Este componente se encarga de hacer las verificaciones necesarias para determinar el estado de un nodo. Los principales chequeos que realiza el componente StatusCheck son los siguientes:
- Visibilidad del nodo al servidor Zabbix
- Estado del agente de Zabbix en el nodo
- Verificación de la cantidad de nodos operativos en el clúster (basado en información de Zabbix)
- Verificación del estatus de cada nodo del clúster (basado en información de Zabbix)
- Invocación del componente CanBeMaster, que se encarga de realizar una verificación interna del PostgreSQL (en el siguiente punto se explica más en detalle)
CanBeMaster: Este componente ejecuta consultas directamente sobre la base de datos, para determinar si ésta puede ser máster. La verificación se ejecuta independientemente del rol actual de la BD (máster/standby), y toma en cuenta tiempos de respuesta, posibles atrasos con respecto al máster, etc.
StatusChange: Si el Keepalived determina que hay que hacer un cambio de estado (con la información que le reporta el StatusCheck), se delega la ejecución a este componente. El StatusChange se encarga de ejecutar todos los cambios de estado posibles (ver tabla más abajo). En particular, si es necesario cambiar el rol de la BD en el nodo local, esta operación se delega al componente Slave2Master o Master2Slave, según corresponda.
Slave2Master: Componente que es lanzado desde el StatusChange cuando hay que promover a máster la instancia PostgreSQL de un nodo.
Master2Slave: Componente que es lanzado desde el StatusChange cuando hay que enganchar como standby la instancia PostgreSQL de un nodo
Zka_nodo3: PGKAZ contempla opcionalmente un “tercer nodo”, que no forma parte del clúster activo. En este nodo se ejecuta el componente zka_nodo3, que verifica continuamente la conectividad a los nodos principales del clúster, así como la conectividad de ellos al servidor Zabbix. Si detecta que el Zabbix no está disponible en al menos un nodo, toma parcialmente el rol de árbitro que tenía Zabbix originalmente.
Adicionalmente, existen dos comunicaciones entre componentes:
- Una comunicación continua (en forma de “pulsos”) entre ambos nodos del clúster (específicamente, entre los componentes Keepalived). Si estos “pulsos” se cortan, también se produce un cambio de estado
- El envío de métricas del cluster al Zabbix, por parte del “StatusCheck”, “StatusChange” y “CanBeMaster”
Monitoreo (Zabbix): Este componente se despliega en forma de “template” en Zabbix y se encarga de “capturar” toda la información del clúster, enviada por los distintos componentes.
Acciones (Zabbix): Este componente funciona de la mano con el “Monitoreo”, de manera que cuando detecta un cambio de condiciones en el clúster, reporta el nuevo estado del clúster a todos los nodos. Esta información es un insumo que será consumido en el próximo ciclo de “Keepalived” por el componente “StatusCheck”.
Diagrama de flujo
El diagrama que se muestra a continuación representa el flujo completo de los estados por los que transita el PGKAZ en cada uno de los nodos HA. Estos estados son los tres que vimos en capítulos anteriores (Máquina de estados del Keepalived y estados de PostgreSQL).
En términos generales, como se comentó anteriormente, la ejecución del PGKAZ consiste en repetir indefinidamente un ciclo de trabajo, idéntico en cada nodo, que en cuyo lapso de tiempo puede atravesar por distintos estados.
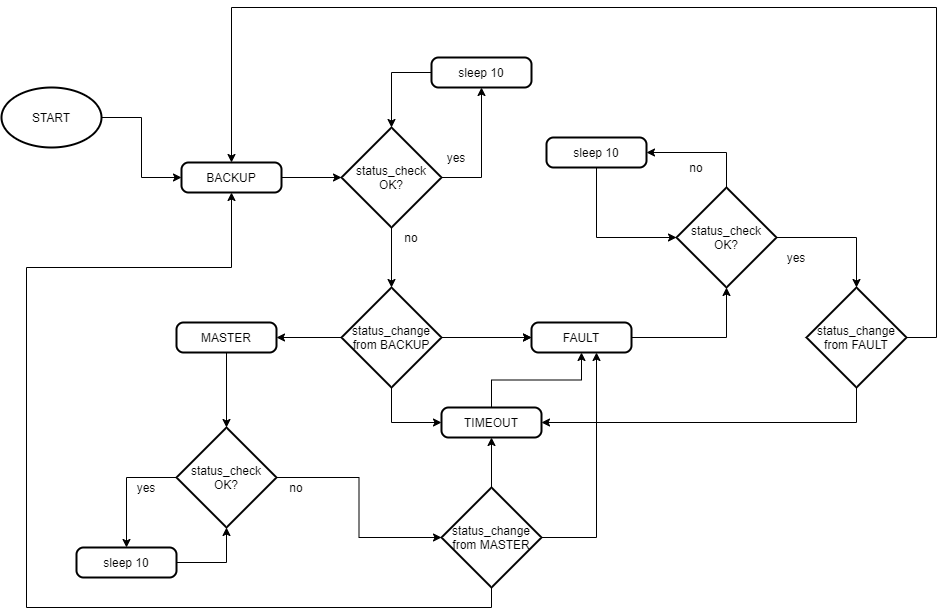
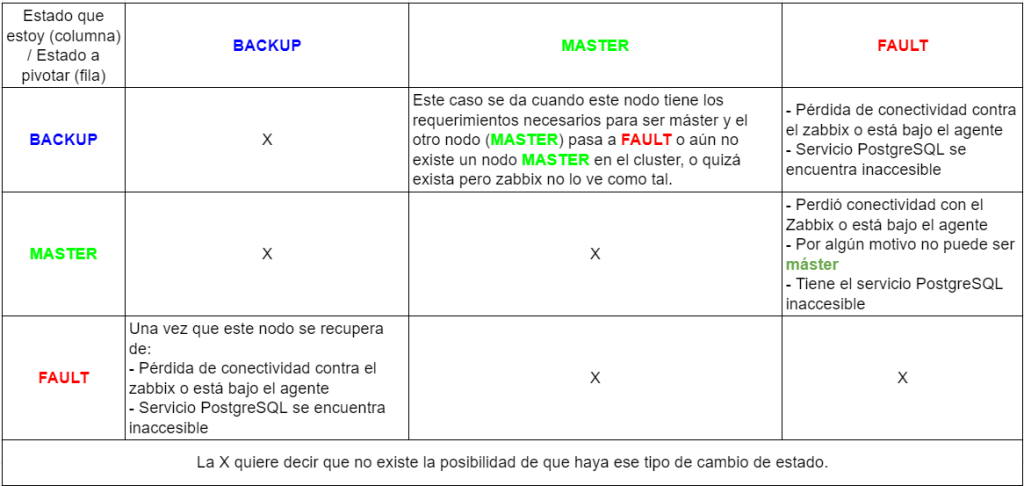
Un nodo siempre va a inicializar en estado BACKUP, luego según como lo procese el StatusCheck es que va a seguir en ese estado, chequeando cada 10 segundos que todo se encuentre normal, o podrá pivotar hacia otro. Como pueden apreciar en la tabla, de BACKUP podemos pivotar hacia MÁSTER o FAULT, dependiendo en las condiciones que nos encontramos (ver tabla de más abajo para apreciar en detalle estas condiciones). El proceso que realiza este cambio de estado es el StatusChange, cuya función además es la de promover (Slave2Master) o enganchar (Master2Slave) los nodos a nivel de PostgreSQL, según el estado al que haya cambiado.
En el caso de cambiar de estado a MASTER, el StatusCheck va a seguir corriendo cada 10 segundos hasta que sucedan algunas condiciones como las que vemos en la tabla (MASTER a FAULT). Por el contrario, si el cambio de estado es a FAULT, la única manera de salir de ese estado es pasando por BACKUP (ver tabla pasaje FAULT a BACKUP).
Por último, lo que falta comentar del diagrama es el TIMEOUT. Muchas veces, por motivos de carga en alguno de los nodos o problemas de intermitencia, los procesos se ejecutan más lento de lo habitual, encolando los procesos y por ende no podemos monitorear correctamente el estado del cluster. Para esto se implementó un TIMEOUT, cuya función es la de mitigar procesos encolados, pero que al mismo tiempo, si el StatusCheck demora más de X tiempo (X es configurable), pasa (indistintamente del estado del que provenía) al estado FAULT.
Consideraciones finales
PGKAZ se implementó con el objetivo de tener un sistema de base de datos con alta disponibilidad, conformado por dos nodos (más un tercero opcional en caso de mayor contingencia) y un Zabbix. Los mismos nos aseguran una disponibilidad absoluta de nuestros datos, teniendo en cuenta que tenemos dos nodos que pueden cambiar de rol constantemente según los problemas que pueda sufrir la infraestructura en donde se encuentran alojados, y un Zabbix que juega un rol muy importante, ya que es el orquestador del cluster. Este último, según en las condiciones que se encuentre cada nodo, va a ser el que tome las decisiones en cuanto a cambios de roles en los nodos. Además, colaborando con la alta disponibilidad, PGKAZ se construyó con la finalidad de que cualquiera sea el mantenimiento que se realice, el sistema siempre se va a encontrar accesible para los usuarios.
Desde Know-How creemos que es una solución robusta, confiable, y apta para cualquier sistema crítico a nivel de disponibilidad. PGKAZ ya forma parte del backend de alguno de nuestros clientes y los resultados, así como el feedback, que hemos obtenido son muy positivos y alentadores.