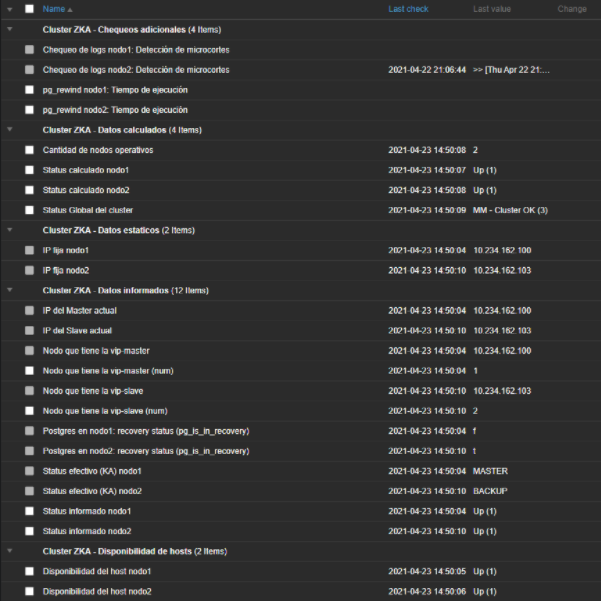
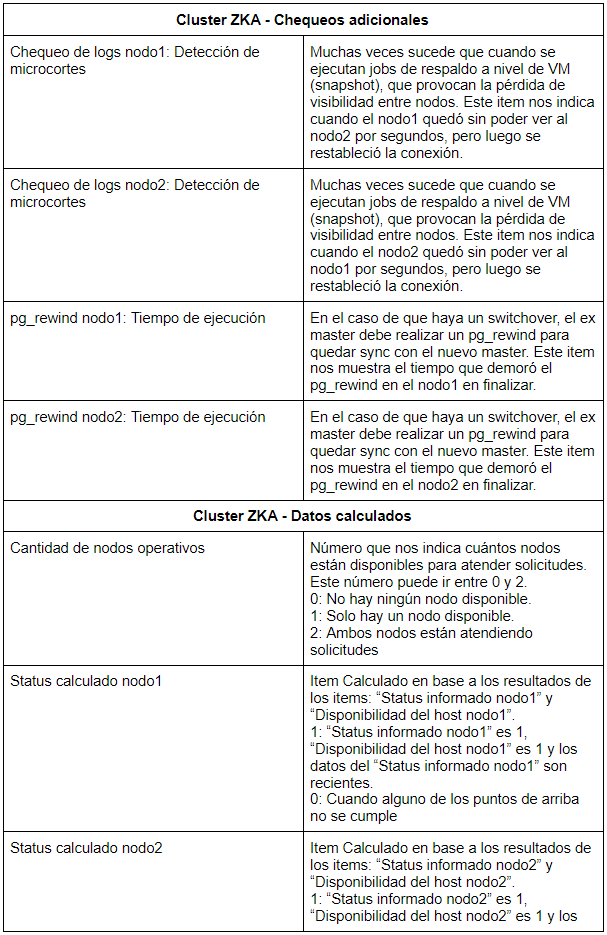
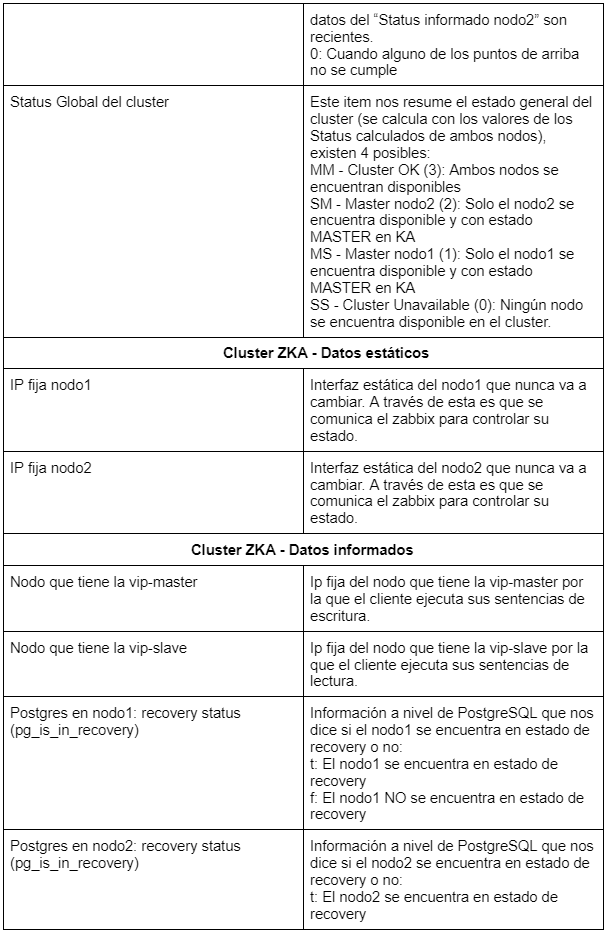
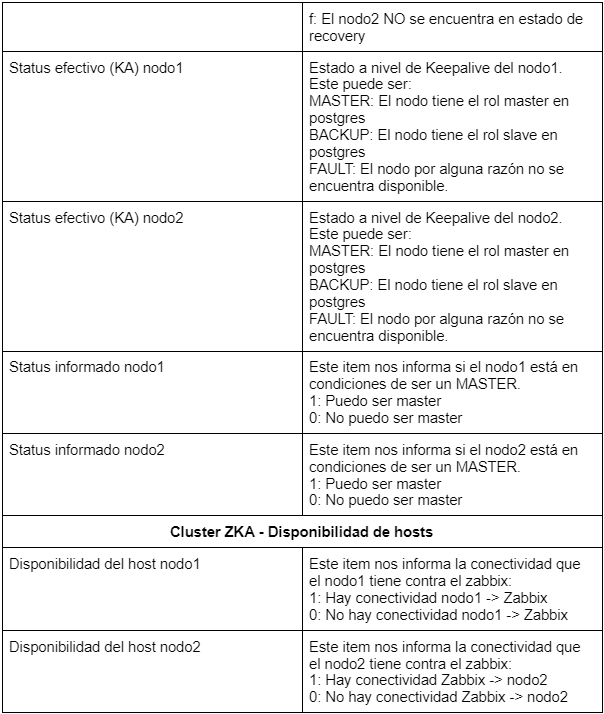
En esta segunda parte del artículo la idea es mostrar, por un lado, qué y cómo visualizamos las distintas métricas obtenidas del cluster PGKAZ y, por el otro, cómo monitoreamos los datos obtenidos. Las métricas en primera instancia son recepcionadas por Zabbix en el formato de “Items”. A continuación les mostramos una captura de los Items con los que contamos y sus valores:
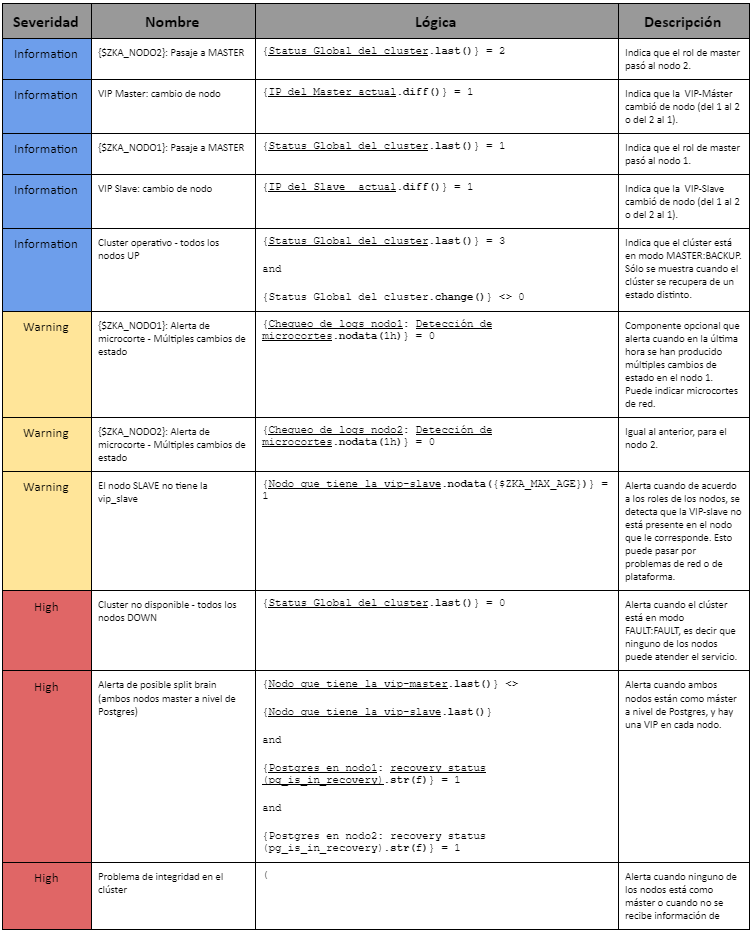
Para que se entienda mejor,qué es lo que representa cada Item, pasamos a enumerar uno por uno en detalle:
Zabbix nos permite mantener un historial de estos Items, graficarlos (en el caso de ser valores numéricos) y al mismo tiempo establecer alertas que nos notifican en caso de que algo no esté funcionando bien. Para cubrir este último punto, Zabbix nos ofrece los Triggers. Estos se construyen a partir de los Items mencionados anteriormente en conjunto con funciones proporcionadas por la herramienta de monitoreo y Macros, donde se establece por lo general ciertos umbrales.
El resumen de los Triggers es el siguiente:
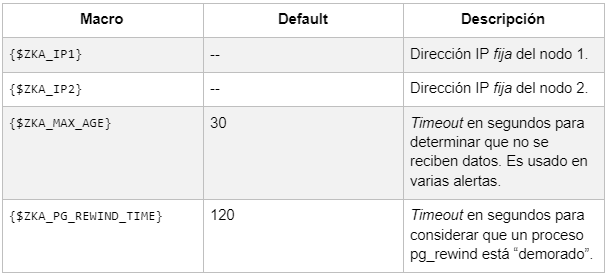
Macros/Variables configurables:.
NOTA: Existen otras variables, pero son internas y no deberían ser modificadas por el operador.
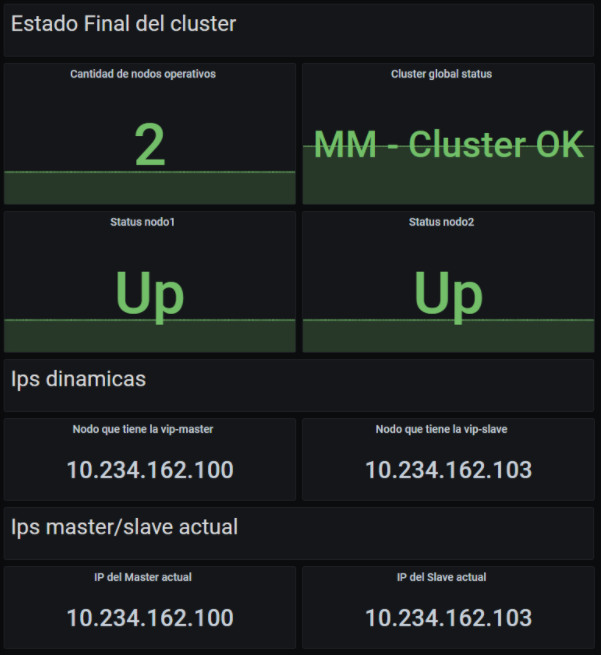
Además del Zabbix, para una mejor visualización de los datos utilizamos Grafana. Esta cuenta con la misma información que Zabbix (de hecho, obtiene los datos en base a un datasource de Zabbix) pero renderizada de una forma más intuitiva y fácil de comprender. A diferencia de Zabbix, en Grafana siempre vamos a tener el snapshot actual del Cluster, lo cual es muy útil cuando se quiere tener una vista a alto nivel del estado del PGKAZ.
Consideraciones finales
Como mencionamos en la primera parte de este artículo, PGKAZ fue implementado para dar servicio a sistemas críticos a nivel de disponibilidad y una pata muy grande para cumplir este requisito es contar con una buena herramienta de monitoreo constante. Zabbix y Grafana nos permiten obtener métricas del estado del cluster que junto a algunos algoritmos configurados permiten optimizar la performance del cluster, saber en todo momento si hubo cambio de roles y porqué, y lo más importante: anticiparnos a futuros incidentes.
Desde Know-How creemos que este sistema de monitoreo implementado es un complemento fundamental al cluster tanto para nosotros (los operadores) como para el cliente, que en todo momento va a poder saber el estado actual (o histórico) del PGKAZ, sin necesidad de consultarnos.