

13.04.2021
Tiempo de lectura estimado: 20 minutos
Introducción del caso
Hace unos días tuvimos la oportunidad de analizar una situación de carga importante en un servidor Linux que corre una instancia MySQL. En condiciones normales de actividad, este servidor normalmente no presenta carga importante, pero en este caso la actividad de la aplicación se disparó en forma importante, llevando la carga a valores muy grandes.
Análisis primario a nivel de Linux
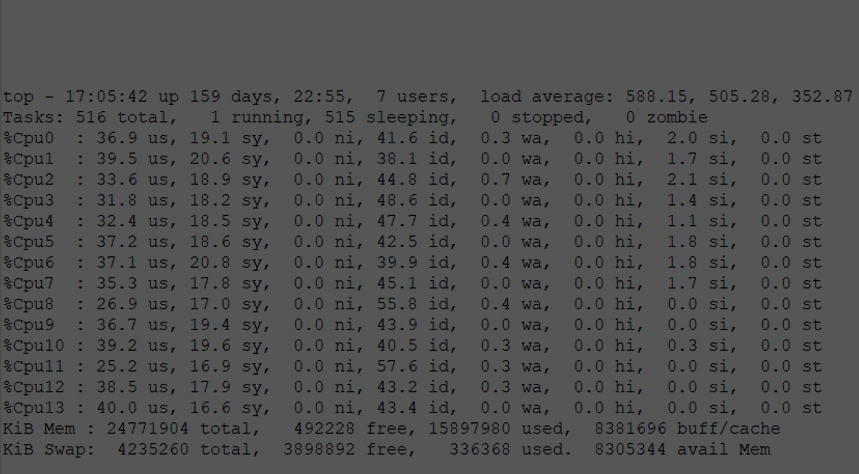
En la siguiente salida del top, vemos el load average en valores de 588 para 1 minuto para el equipo que tiene 14 cores, llegando a valores de más de 900 como se ve normalizado por cantidad de cpus en la gráfica siguiente a la salida del top:


En la siguiente gráfica se ve la carga normalizada por cantidad de cores para intervalos de 1 minuto. Por ejemplo, el pico máximo de 64.72 que indica la gráfica, se corresponde al pico máximo de más de 900 que comentamos antes que llegamos a visualizar en el top (64.72 * 14 = 906 ).

Llama la atención, que, aunque el servidor tenga tanta carga, las 14 cpus tengan entre 40% y 50% de su CPU idle.
En resumen, observamos a nivel de Linux:
- Bajo consumo de CPU en términos de %USU, %SYS, %WAIT. O sea, desde otro punto de vista: nivel alto de %IDLE.
- Bajo consumo de I/O en términos de MB/sec a/desde almacenamiento
- Load average MUY alto.
Análisis primario a nivel de MySQL
A nivel de MySQL, se tenían al momento del análisis, poco menos de 700 sesiones, casi todas activas en el mismo momento y ejecutando una misma query que tenía excelente plan de acceso, de hecho, al ejecutar la query en esa situación de carga, la misma devolvía el resultado en forma inmediata. El State que mostraba el show processlist de MySQL para casi todas las sesiones era “Sending data” y “removing tmp table” y la columna Time mostraba 0 para todas las ejecuciones, indicando que para ese show processlist, esa query llevaba menos de 1 segundo activa. Al repetir sucesivas e inmediatas tomas del show processlist, la situación era la misma (siempre Time en 0), lo cual nos confirmaba que efectivamente esa query demoraba menos de 1 segundo:
root@prod01 [(none)] > show processlist; +----------+-------------+----------------------+--------------+-------------+-------+-----------------------------------------------------------------------+------------------------------------------------------------------------------------------------------+ | Id | User | Host | db | Command | Time | State | Info | +----------+-------------+----------------------+--------------+-------------+-------+-----------------------------------------------------------------------+------------------------------------------------------------------------------------------------------+ | 9332616 | user01 | 10.233.110.25:24187 | proddb01 | Sleep | 27629 | | NULL | ... | 11884350 | user01 | 10.233.110.46:45485 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11884676 | user01 | 10.233.110.46:45605 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11884678 | user01 | 10.233.10.46:34021 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11884835 | user01 | 10.233.10.46:34071 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11884836 | user01 | 10.233.10.45:62921 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885048 | user01 | 10.233.110.46:45733 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885134 | user01 | 10.233.110.45:42018 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885242 | user01 | 10.233.110.45:42064 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885246 | user01 | 10.233.10.25:51831 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885266 | user01 | 10.233.110.45:42072 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885381 | user01 | 10.233.10.46:34299 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885425 | user01 | 10.233.10.45:63161 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885434 | user01 | 10.233.110.25:38595 | prodbp | Query | 0 | statistics | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885440 | user01 | 10.233.110.45:42146 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885455 | user01 | 10.233.10.25:51923 | prodbp | Sleep | 0 | | NULL | | 11885519 | user01 | 10.233.10.46:34371 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885541 | user01 | 10.233.110.46:45903 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885564 | user01 | 10.233.110.46:45911 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885636 | user01 | 10.233.110.46:45929 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885638 | user01 | 10.233.10.46:34427 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885642 | user01 | 10.233.10.45:63231 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885673 | user01 | 10.233.10.45:63245 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885713 | user01 | 10.233.110.46:45957 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885714 | user01 | 10.233.10.25:52027 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885722 | user01 | 10.233.110.46:45971 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885748 | user01 | 10.233.10.25:52041 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885794 | user01 | 10.233.10.25:52063 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885855 | user01 | 10.233.110.25:38777 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885959 | user01 | 10.233.10.45:63345 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885966 | user01 | 10.233.110.45:42302 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885982 | user01 | 10.233.110.46:46107 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11885994 | user01 | 10.233.10.25:52137 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886033 | user01 | 10.233.110.25:38877 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886034 | user01 | 10.233.110.46:46129 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886077 | user01 | 10.233.110.45:42328 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886171 | user01 | 10.233.110.25:38933 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886189 | user01 | 10.233.10.45:63397 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886194 | user01 | 10.233.10.46:34701 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886233 | user01 | 10.233.10.46:34711 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886252 | user01 | 10.233.110.45:42376 | prodbp | Sleep | 0 | | NULL | | 11886340 | user01 | 10.233.110.25:38985 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886398 | user01 | 10.233.10.25:52347 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886458 | user01 | 10.233.110.25:39039 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886527 | user01 | 10.233.110.45:42470 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886545 | user01 | 10.233.110.45:42474 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886551 | user01 | 10.233.110.46:46359 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886596 | user01 | 10.233.110.45:42494 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886642 | user01 | 10.233.110.46:46411 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886684 | user01 | 10.233.110.25:39119 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886822 | user01 | 10.233.110.45:42622 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886829 | user01 | 10.233.110.25:39177 | prodbp | Query | 0 | Sending data | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__etapa_id, e.id AS | | 11886844 | user01 | 10.233.10.46:34975 | prodbp | Query | 0 | removing tmp table | SELECT d.id AS d__id, d.nombre AS d__nombre, d.valor AS d__valor, d.etapa_id AS d__ ... | 11893368 | user01 | 10.233.110.25:41671 | prodbp | Sleep | 0 | | NULL | | 11893369 | user01 | 10.233.10.25:54849 | prodbp | Sleep | 0 | | NULL | +----------+-------------+----------------------+--------------+-------------+-------+-----------------------------------------------------------------------+------------------------------------------------------------------------------------------------------+ 637 rows in set (0.00 sec)
La carga no estaba dada por una query mal escrita o no optimizada (no planteamos la query completa y su análisis en este artículo porque el propósito del mismo no va por ese lado) o mala configuración de innodb buffer caché puesto que el buffer hit ratio estaba arriba del 99,5% y con margen de memoria libre en el buffer. Todo apuntaba a que la carga se disparaba por la gran actividad concurrente que se daba por momentos, en algunos casos hasta casi 1000 sesiones activas ejecutando la misma query.
Atando cabos: Load average, uso de cpu, estados ininterrumpibles y uso de temporales
Como comentamos antes, llamaba la atención que aun con tanta carga, las cpus estuvieran idle en un alto porcentaje y además el top nos mostraba porcentajes muy bajos de wait (menores a 1%), por lo que no había una espera importante por I/O según los indicadores que analizábamos en el top.
De todas formas, en los valores de load average, especialmente en Linux, sabemos que se tienen en cuenta no sólo el uso “normal” de CPU por parte de procesos o hilos, sino también estados ininterrumpibles de los threads. En general estos estados ininterrumpibles están asociados a I/O.
Del man uptime:
DESCRIPTION uptime gives a one line display of the following information. The current time, how long the system has been running, how many users are currently logged on, and the system load averages for the past 1, 5, and 15 minutes. This is the same information contained in the header line displayed by w(1). System load averages is the average number of processes that are either in a runnable or uninterruptable state. A process in a runnable state is either using the CPU or waiting to use the CPU. A process in uninterruptable state is waiting for some I/O access, eg waiting for disk. The averages are taken over the three time intervals. Load averages are not normalized for the number of CPUs in a system, so a load average of 1 means a single CPU system is loaded all the time while on a 4 CPU system it means it was idle 75% of the time.
Y si se quiere profundizar en el estado ininterrumpible considerado en load averages y su origen, recomendamos el siguiente blog:
http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html
Así que analizamos con ps para ver si tenemos threads en estado ininterrumpibles.
Del man ps:
PROCESS STATE CODES
Here are the different values that the s, stat and state output specifiers (header "STAT" or "S") will display to describe the state of a process:
D uninterruptible sleep (usually IO)
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
T stopped by job control signal
t stopped by debugger during the tracing
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z defunct ("zombie") process, terminated but not reaped by its parent
Así pues, buscamos por threads de mysql con State D (uninterruptible sleep):
[mysql@prod01 master /srv/backups]$ ps -eo ppid,pid,user,stat,pcpu,comm,wchan:32 -T | grep mysql | grep Dl|wc -l 547 [mysql@prod01 master /srv/backups]$ uptime 18:11:03 up 160 days, 1 min, 11 users, load average: 615.86, 612.22, 581.42 [mysql@prod01 master /srv/backups]$ ps -eo ppid,pid,user,stat,pcpu,comm,wchan:32 -T | grep mysql | grep Dl | grep unlinkat 17043 17608 mysql Dl 0.0 mysqld unlinkat 17043 17608 mysql Dl 0.3 mysqld unlinkat 17043 17608 mysql Dl 0.4 mysqld unlinkat 17043 17608 mysql Dl 0.3 mysqld unlinkat 17043 17608 mysql Dl 0.4 mysqld unlinkat 17043 17608 mysql Dl 0.4 mysqld unlinkat 17043 17608 mysql Dl 0.3 mysqld unlinkat 17043 17608 mysql Dl 0.3 mysqld unlinkat
El flag wchan (waiting channel) indica la función del kernel en la que está durmiendo el proceso y en nuestro caso, para la mayoría de los threads nos mostraba unlinkat(), que según confirmamos (ver https://www.man7.org/linux/man-pages/man2/unlinkat.2.html) es una función para borrar archivos de un filesystem.
Este dato estaba alineado con uno de los estados “removing tmp table” que veíamos a las sesiones en la instancia MySQL y lo pudimos corroborar aún más, inspeccionando el directorio tmpdir de la instancia MySQL, donde pudimos observar la gran cantidad de temporales que se generaban y se eliminaban rápidamente, a tal punto que el comando ls no podía mostrar (o los mostraba mal sin información de permisos, owner, tamaño y fecha) algunos de esos archivos temporales de MySQL que detectaba en el directorio pero que desaparecían rápidamente:
[mysql@prod01 master /srv/mysqldata/tmp]$ ls -ltr ls: cannot access #sql_44c8_328.MYD: No such file or directory ls: cannot access #sql_44c8_328.MYI: No such file or directory ls: cannot access #sql_44c8_467.MYD: No such file or directory ls: cannot access #sql_44c8_437.MYI: No such file or directory ls: cannot access #sql_44c8_447.MYD: No such file or directory ls: cannot access #sql_44c8_451.MYD: No such file or directory ls: cannot access #sql_44c8_467.MYI: No such file or directory total 1308 ??????????? ? ? ? ? ? #sql_44c8_467.MYI ??????????? ? ? ? ? ? #sql_44c8_467.MYD ??????????? ? ? ? ? ? #sql_44c8_451.MYD ??????????? ? ? ? ? ? #sql_44c8_447.MYD ??????????? ? ? ? ? ? #sql_44c8_437.MYI ??????????? ? ? ? ? ? #sql_44c8_328.MYI ??????????? ? ? ? ? ? #sql_44c8_328.MYD -rw-rw----. 1 mysql mysql 76 Mar 16 18:27 #sql_44c8_155.MYD -rw-rw----. 1 mysql mysql 76 Mar 16 18:27 #sql_44c8_463.MYD -rw-rw----. 1 mysql mysql 80 Mar 16 18:27 #sql_44c8_516.MYD -rw-rw----. 1 mysql mysql 80 Mar 16 18:27 #sql_44c8_68.MYD -rw-rw----. 1 mysql mysql 76 Mar 16 18:27 #sql_44c8_24.MYD -rw-rw----. 1 mysql mysql 0 Mar 16 18:27 #sql_44c8_535.MYD -rw-rw----. 1 mysql mysql 0 Mar 16 18:27 #sql_44c8_84.MYD -rw-rw----. 1 mysql mysql 80 Mar 16 18:27 #sql_44c8_75.MYD -rw-rw----. 1 mysql mysql 0 Mar 16 18:27 #sql_44c8_476.MYD …. -rw-rw----. 1 mysql mysql 1024 Mar 16 18:27 #sql_44c8_160.MYI -rw-rw----. 1 mysql mysql 0 Mar 16 18:27 #sql_44c8_160.MYD -rw-rw----. 1 mysql mysql 80 Mar 16 18:27 #sql_44c8_432.MYD -rw-rw----. 1 mysql mysql 1024 Mar 16 18:27 #sql_44c8_427.MYI -rw-rw----. 1 mysql mysql 0 Mar 16 18:27 #sql_44c8_427.MYD -rw-rw----. 1 mysql mysql 0 Mar 16 18:27 #sql_44c8_153.MYD -rw-rw----. 1 mysql mysql 0 Mar 16 18:27 #sql_44c8_152.MYI -rw-rw----. 1 mysql mysql 1024 Mar 16 18:27 #sql_44c8_432.MYI -rw-rw----. 1 mysql mysql 1024 Mar 16 18:27 #sql_44c8_158.MYI -rw-rw----. 1 mysql mysql 76 Mar 16 18:27 #sql_44c8_158.MYD -rw-rw----. 1 mysql mysql 76 Mar 16 18:27 #sql_44c8_434.MYD -rw-rw----. 1 mysql mysql 76 Mar 16 18:27 #sql_44c8_173.MYD -rw-rw----. 1 mysql mysql 1024 Mar 16 18:27 #sql_44c8_341.MYI -rw-rw----. 1 mysql mysql 76 Mar 16 18:27 #sql_44c8_341.MYD -rw-rw----. 1 mysql mysql 1024 Mar 16 18:27 #sql_44c8_192.MYI [mysql@prod01 master /srv/mysqldata/tmp]$
Ya habíamos intentado minimizar las sesiones MySQL en ese estado sin éxito, aumentando las variables de configuración max_heap_table_size y tmp_table_size, pasándolas de 32M a 64M. La solución no pasaba por ahí ya que estos archivos temporales no superaban los 1024bytes de tamaño y eran generados siempre por MySQL al ejecutarse la consulta, más allá de la configuración de estos parámetros MySQL.
Lo que hicimos entonces, fue configurar el tmpdir de la instancia MySQL en un sistema de archivos montado sobre un ramdisk, con la idea de minimizar la creación y eliminación de esos temporales en disco y poder con ello minimizar la cantidad de threads en estado ininterrumplible con el objetivo final de bajar la carga.
Creamos el ramdisk:
root@prod01:~# mkdir -p /srv/mysqldata/tmpram root@prod01:~# chown mysql.mysql /srv/mysqldata/tmpram root@prod01:~# vi /etc/fstab root@prod01:~# cat /etc/fstab | grep -i tmpram tmpfs /srv/mysqldata/tmpram tmpfs size=3072M 0 0 root@prod01:~# mount -t tmpfs -o size=3072M tmpfs /srv/mysqldata/tmpram root@prod01:~# df -hTP /srv/mysqldata/tmpram Filesystem Type Size Used Avail Use% Mounted on tmpfs tmpfs 3.0G 0 3.0G 0% /srv/mysqldata/tmpram root@prod01:~#
Seteamos la variable tmpdir de MySQL apuntando al path del ramdisk (requiere reinicio de la instancia MySQL):
root@prod01 [(none)] > show global variables like 'tmpdir'; +---------------+-----------------------+ | Variable_name | Value | +---------------+-----------------------+ | tmpdir | /srv/mysqldata/tmpram | +---------------+-----------------------+ 1 row in set (0.00 sec)
Ahora analizamos nuevamente el comportamiento de la instancia MySQL y vemos que tenemos en forma constante más de 850 sesiones activas concurrentes. En particular, marcamos en rojo las que veníamos analizando previamente y están con máximo tiempo de ejecución en 0 segundos:
root@prod01 [(none)] > select command, substr(info,1,10) , count(1), max(time) from information_schema.processlist group by command, substr(info,1,10);
+-------------+-------------------+----------+-----------+
| command | substr(info,1,10) | count(1) | max(time) |
+-------------+-------------------+----------+-----------+
| Binlog Dump | NULL | 1 | 58685 |
| Query | INSERT INT | 6 | 0 |
| Query | SELECT a.i | 5 | 0 |
| Query | SELECT c.i | 10 | 0 |
| Query | select com | 1 | 0 |
| Query | select COU | 2 | 8 |
| Query | SELECT d.i | 687 | 0 |
| Query | SELECT e.i | 145 | 0 |
| Query | SELECT f.i | 3 | 0 |
| Query | SELECT p.i | 5 | 0 |
| Query | SELECT t.i | 13 | 0 |
| Query | SELECT tra | 6 | 434 |
| Query | SELECT u.i | 11 | 0 |
| Query | UPDATE dat | 2 | 0 |
| Query | UPDATE eta | 1 | 0 |
| Sleep | NULL | 60 | 3408 |
+-------------+-------------------+----------+-----------+
16 rows in set (0.13 sec)
root@prod01 [(none)] >
Revisamos a nivel de Linux con top y ahora vemos una carga de 27 y el porcentaje de cpu idle mucho menor de lo que teníamos en la situación original (19% idle ahora vs 45% idle en principio, en promedio por cpu. Esto es, ahora las CPU “trabajan más”):
top - 11:07:30 up 161 days, 16:57, 7 users, load average: 27.16, 25.34, 18.17 Tasks: 520 total, 1 running, 519 sleeping, 0 stopped, 0 zombie %Cpu0 : 51.0 us, 32.2 sy, 0.0 ni, 14.1 id, 0.0 wa, 0.0 hi, 2.7 si, 0.0 st %Cpu1 : 45.1 us, 34.9 sy, 0.0 ni, 17.6 id, 0.0 wa, 0.0 hi, 2.4 si, 0.0 st %Cpu2 : 45.9 us, 33.3 sy, 0.0 ni, 18.4 id, 0.0 wa, 0.0 hi, 2.4 si, 0.0 st %Cpu3 : 39.7 us, 36.6 sy, 0.0 ni, 21.0 id, 0.0 wa, 0.0 hi, 2.7 si, 0.0 st %Cpu4 : 41.8 us, 36.8 sy, 0.0 ni, 18.7 id, 0.0 wa, 0.0 hi, 2.7 si, 0.0 st %Cpu5 : 43.9 us, 35.0 sy, 0.0 ni, 18.0 id, 0.0 wa, 0.0 hi, 3.1 si, 0.0 st %Cpu6 : 41.9 us, 36.5 sy, 0.0 ni, 19.6 id, 0.0 wa, 0.0 hi, 2.0 si, 0.0 st %Cpu7 : 42.6 us, 36.6 sy, 0.0 ni, 19.1 id, 0.0 wa, 0.0 hi, 1.7 si, 0.0 st %Cpu8 : 47.3 us, 33.2 sy, 0.0 ni, 19.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu9 : 44.6 us, 34.8 sy, 0.0 ni, 20.3 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu10 : 46.8 us, 34.0 sy, 0.0 ni, 18.5 id, 0.7 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu11 : 40.6 us, 36.2 sy, 0.0 ni, 22.8 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu12 : 42.6 us, 36.2 sy, 0.0 ni, 20.8 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu13 : 39.9 us, 37.5 sy, 0.0 ni, 22.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 27917632 total, 196992 free, 14916400 used, 12804240 buff/cache KiB Swap: 4235260 total, 3988916 free, 246344 used. 12517660 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9859 mysql 20 0 20.758g 0.013t 6048 S 1114 51.0 1479:57 mysqld 137 root 20 0 0 0 0 S 0.7 0.0 252:49.95 rcu_sched 139 root 20 0 0 0 0 S 0.7 0.0 31:30.03 rcuos/1 140 root 20 0 0 0 0 S 0.3 0.0 30:11.17 rcuos/2 141 root 20 0 0 0 0 S 0.3 0.0 29:45.01 rcuos/3 144 root 20 0 0 0 0 S 0.3 0.0 29:08.54 rcuos/6 145 root 20 0 0 0 0 S 0.3 0.0 29:25.65 rcuos/7 146 root 20 0 0 0 0 S 0.3 0.0 15:51.68 rcuos/8 147 root 20 0 0 0 0 S 0.3 0.0 21:07.92 rcuos/9 148 root 20 0 0 0 0 S 0.3 0.0 4:30.63 rcuos/10 149 root 20 0 0 0 0 S 0.3 0.0 4:48.58 rcuos/11
Analizamos ahora los estados de las sesiones y vemos más estados que antes (antes casi todas las sesiones estaban en “Sending data” o “removing tmp table”):
root@prod01 [(none)] > select state, count(1) from information_schema.processlist group by state; +------------------------------------------------------------------+----------+ | state | count(1) | +------------------------------------------------------------------+----------+ | | 76 | | cleaning up | 1 | | closing tables | 45 | | Creating sort index | 2 | | executing | 1 | | init | 1 | | Master has sent all binlog to slave; waiting for binlog to be up | 1 | | Opening tables | 69 | | preparing | 1 | | removing tmp table | 160 | | Sending data | 433 | | statistics | 6 | +------------------------------------------------------------------+----------+ 12 rows in set (0.13 sec) root@prod01 [(none)] >
En particular, vemos unas cuantas sesiones con estados “closing tables” y “Opening tables”, por lo que ampliamos el parámetro table_open_cache, pasándolo de 2000 a 100000 para mitigar esto:
root@prod01 [(none)] > set global table_open_cache=100000; Query OK, 0 rows affected (0.00 sec) root@prod01 [(none)] > show global variables like 'table_open_cac%'; +----------------------------+--------+ | Variable_name | Value | +----------------------------+--------+ | table_open_cache | 100000 | | table_open_cache_instances | 1 | +----------------------------+--------+ 2 rows in set (0.00 sec) root@prod01 [(none)] >
y ahora bajaron las sesiones en esos estados:
root@prod01 [(none)] > select state, count(1) from information_schema.processlist group by state; +------------------------------------------------------------------+----------+ | state | count(1) | +------------------------------------------------------------------+----------+ | | 88 | | cleaning up | 2 | | Creating sort index | 1 | | Creating tmp table | 1 | | executing | 1 | | Master has sent all binlog to slave; waiting for binlog to be up | 1 | | preparing | 2 | | removing tmp table | 217 | | Sending data | 509 | | statistics | 6 | +------------------------------------------------------------------+----------+ 10 rows in set (0.20 sec)
Queda por revisar a nivel de ps, si tenemos threads de mysql en estado ininterrumpibles:
[mysql@prod01 master ~]$ ps -eo ppid,pid,user,stat,pcpu,comm,wchan:32 -T | grep mysql | grep Dl|wc -l 0 [mysql@prod01 master ~]$
No tenemos más threads en estado D (ininterrumpible), puesto que los archivos temporales que genera MySQL los está generando ahora en el ramdisk.
Mejoras obtenidas
Vemos gráficamente como, a igual actividad de la aplicación, con los cambios aplicados, el load average del servidor bajó radicalmente (inicialmente teníamos 65 de máximo y ahora 2):

También vemos como el cambio mejoró el uso de CPU, logrando un mayor uso de este recurso:
Antes:

Después:

A nivel de queries por segundo en la instancia MySQL, también se vieron las mejoras, pasando de un promedio de 4000 por segundo y máximo de 8000 por segundo a un promedio de 11000 por segundo y máximo de 17000 por segundo.
Antes:

Después:

Comentarios finales
Mas allá de compartir como optimizamos este caso particular y real logrando una mejora importante en la performance del sistema, una mejora en el uso del recurso CPU y mejorando los indicadores de carga, queríamos compartir también como los resultados del análisis de diferentes indicadores a nivel de la base de datos y del sistema operativo, van “cerrando” y logran explicar determinadas situaciones que nos podemos encontrar cuando hacemos este tipo de análisis.
Autor:
Alejandro Cristiani, Director de Know-How y DBA Sr.


