


10.09.21
Tiempo estimado: 6 minutos
En repetidas ocasiones a los DBA se nos presenta el gran reto de administrar bases con tablas que almacenan varios millones de registros, con espacio en disco acotado y sin dejar de mantener a los usuarios satisfechos. La performance, operatividad y volumen de la base, entre otras, son las premisas con las que trabajamos diariamente.
Siempre hemos estudiado que utilizar particionado en las tablas nos ayuda a incrementar el desempeño de las consultas de nuestra app. Tanto es así que se recomienda su uso desde el comienzo, incluso es aplicable en bases de datos existentes.
Basada en mi experiencia de muchos años, quiero compartir otro uso del particionamiento y espero que les resulte tremendamente efectivo como a mí.
Sabemos que la depuración de los datos es todo un capítulo complicado pero necesario en la vida útil de una base, consumiéndonos tiempo y mucho esfuerzo. El “kick off” lo dieron los desarrolladores, definiendo una primer tabla a depurar, y se dieron cuenta que la solución no era un script con la DML delete. Entonces se nos invitó a participar.
Después de valorar el uso/llenado del transaction log, cada cuantos regs. hacer commit, llenado de fs, cantidad generada de archivelogs (binlogs) para aplicar en el slave, etc.; la tarea quedó de nuestro lado.
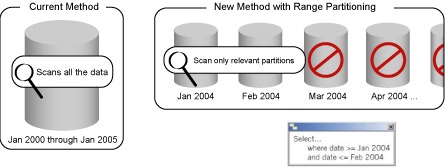
Utilizamos el particionamiento para depurar tablas de forma tal que el esfuerzo se enfoca exclusivamente en definir las particiones con su índice y la implementación del mecanismo de detach o desacolpamiento de la partición.
Como si fuera poco, se suma que no requiere mantenimiento y puede aplicarse en cualquier motor que cuente con la característica de particionado. Si continúan leyendo, se darán cuenta de porqué menciono esto.
Este artículo describe la implementación de un caso real ante el cual se pueden enfrentar en cualquier circunstancia:
Tenía una tabla de millones de registros y debía mantener un histórico de 6 meses. El índice de particionamiento elegido fue el mes numérico. En este caso la tabla no contaba con el campo fecha, por supuesto tampoco con el campo mes. Esto no fue impedimento, busqué la forma de generarlo tratando de que no afectara la app.
Por cada registro insertado, se grabó también el campo fecha (CURRENT DATE) y de ese campo quité el mes para ver en que partición debía insertarse cada uno.
Como comenté anteriormente, el esfuerzo se hizo al inicio para cambiar la estructura de la tabla, definiendo dos campos nuevos y 12 particiones correspondiente una a cada mes del año.
Luego se realizó la migración de la tabla en forma coordinada, en una ventana definida para que afectara lo menos posible la producción.
Una vez que se completó el mes número 6 y comencé a insertar el próximo, se desacopló (detach) la partición que tiene los regs. con 6 meses de antigüedad y se hizo cíclico, sin tener que crear más particiones aunque cambiara el año. Es decir, cuando mi tabla comenzó a insertar en la partición del mes mayo (según figura), se hizo el detach de enero y así solo mantuve los meses necesarios en línea. Al cambiar de año no debí hacer nada, las particiones ya estaban creadas porque las reusamos, lo cual estableció una gran ventaja que nos salvó y salvará de olvidos tan comunes.
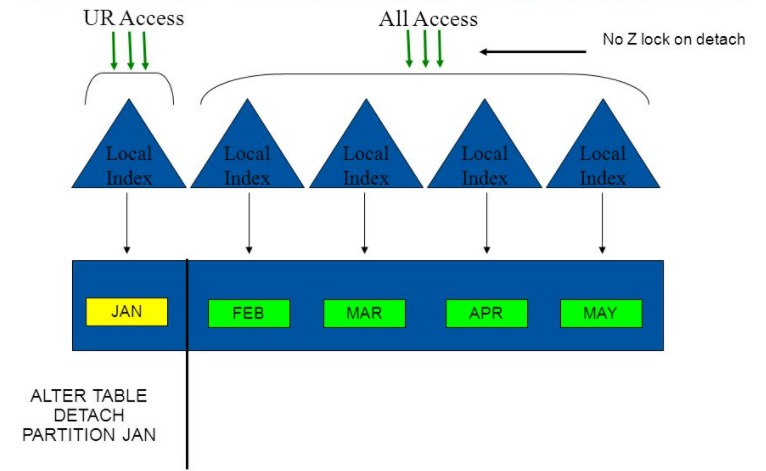
El usar particiones no es mágico, ya que existe un tiempo de AIC (Asynchronous index cleanup) al desacoplar una partición. Sin embargo, es una forma práctica de eliminar cantidades elevadas de registros con el menor esfuerzo, de lo contrario la tarea se hace repetitiva y nos consume todas nuestras horas.
Por ejemplo, en algunos motores, esta reorganización de los índices es diferida y en background. Las queries ignoran cualquier índice marcado inválido que no haya sido eliminado aún y el acceso a la tabla es normal.
Por lo tanto, si comienzan a crear una base desde 0, en caso de tener tablas grandes, no olviden tener en cuenta posibles procesos de depuración
para lo cual la funcionalidad de particionamiento de tablas puede resultarles muy útil!
Autora: Rosana Garrone, DBA Sr.


